LAT Data Processing Facility
Function
This Pipeline facility has five major functions:
· automatically process Level 0 data
through reconstruction (Level 1)
· provide near real-time feedback to
IOC
· facilitate the verification and
generation of new calibration constants
· produce bulk Monte Carlo
simulations
· backup all data that passes through
The pipeline database and server, and diagnostics
database have been specified.
|
 |
Implementation
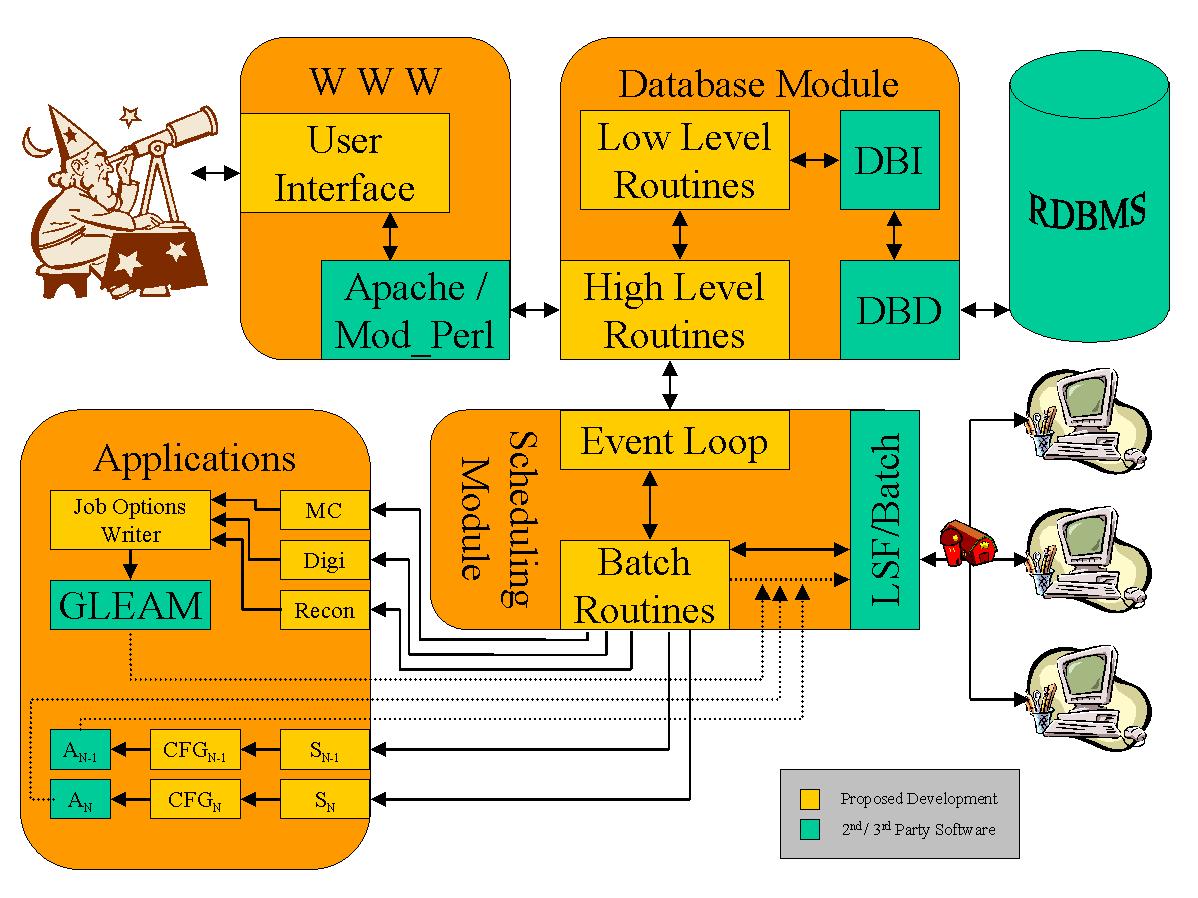
The Pipeline can be expressed as five components:
1. database access layer
2. execution layer
3. scheduler
4. user interface
5. relational database (management system): RDBMS
The scheduler is the main loop of the Pipeline. This long
running process polls the database for new tasks, and dispatches
processes to the execution layer.
The execution layer exists to abstract site specific details
about how computing resources are invoked. It handles launching
jobs and collecting output. At SLAC, this will be a thin wrapper
around the LSF batch system toolchain. Other implementations will
support simple clusters of machines using SSH for remote
invocation, and single machine use where jobs are launched on
same machine as scheduler.
The database access module contains all SQL queries and
statements required by other parts of the system. By keeping the
rest of the system from knowing anything about the database, we
isolate from changes to both the schema and the database engine.
The RDBMS is an Oracle instance, hosted by SCS. We will use
the DPF schema that has already been designed. (LAT-TD-00553-D1)
'The Plan':
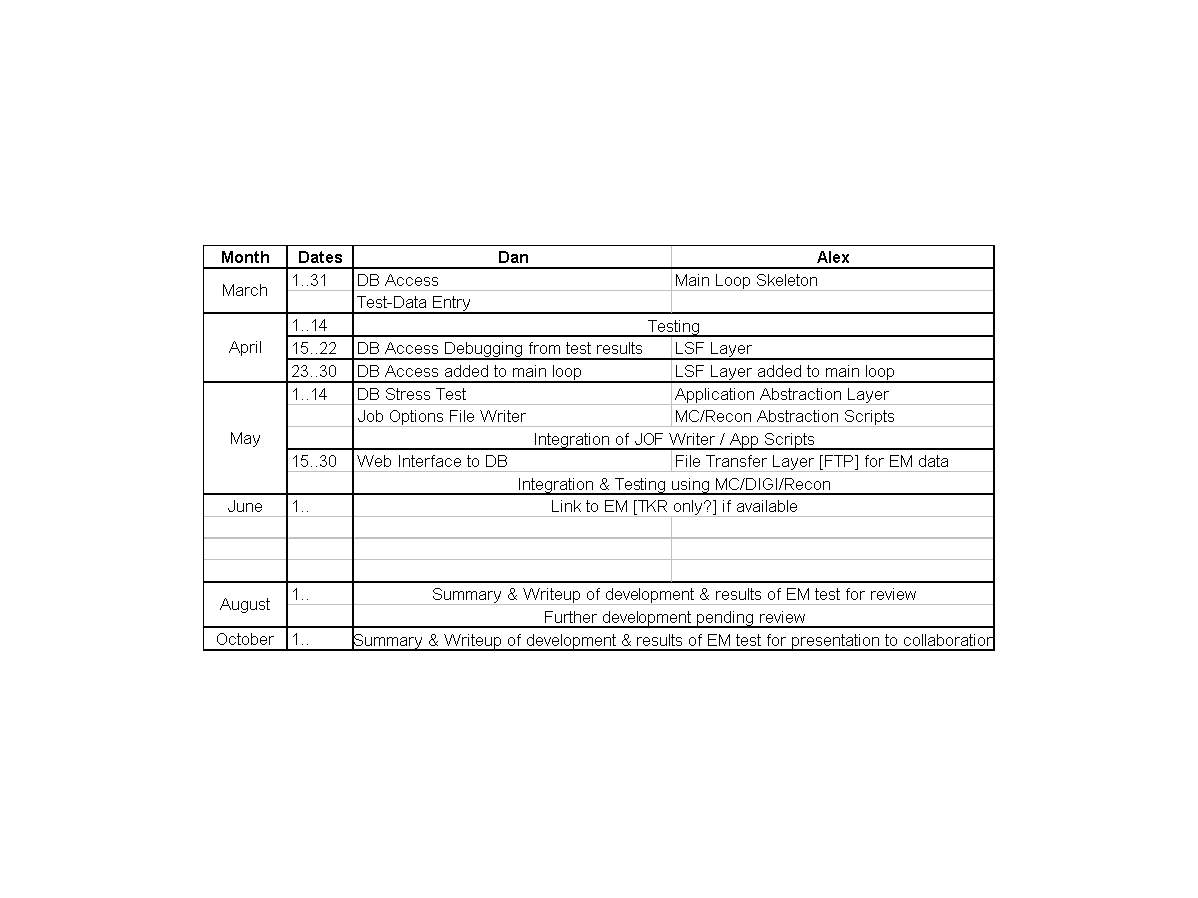
The DPF is now under development by Alex Schlessinger (SLAC)
and Daniel Flath (Stanford). A prototype design and a development
schedule are underway.
- A design document describing each component and
implementation details is being written and a first draft is available here.
The prototype will undergo it's first live test with
Engineering Model data summer, 2003. Results of this trial, prior
and subsequent development, and recommendations for the future
will be presented in November during the Peer Review.
Last Modified: 2003-03-11 16:37:36 PST
{kind=link}
{kind=link}